


作者:中联科创特约嘉宾尹智
大模型是好,何以为我用?—— 前一阵写了篇东西,预测了一下大模型的"瘦身"之路,从附图的介绍来看,预期的这些思路正在快速得到实现,现在利用大模型技术的思路,除掉云服务(不能训练提供云服务的大模型的参数),私有化部署无非就是三个模式;
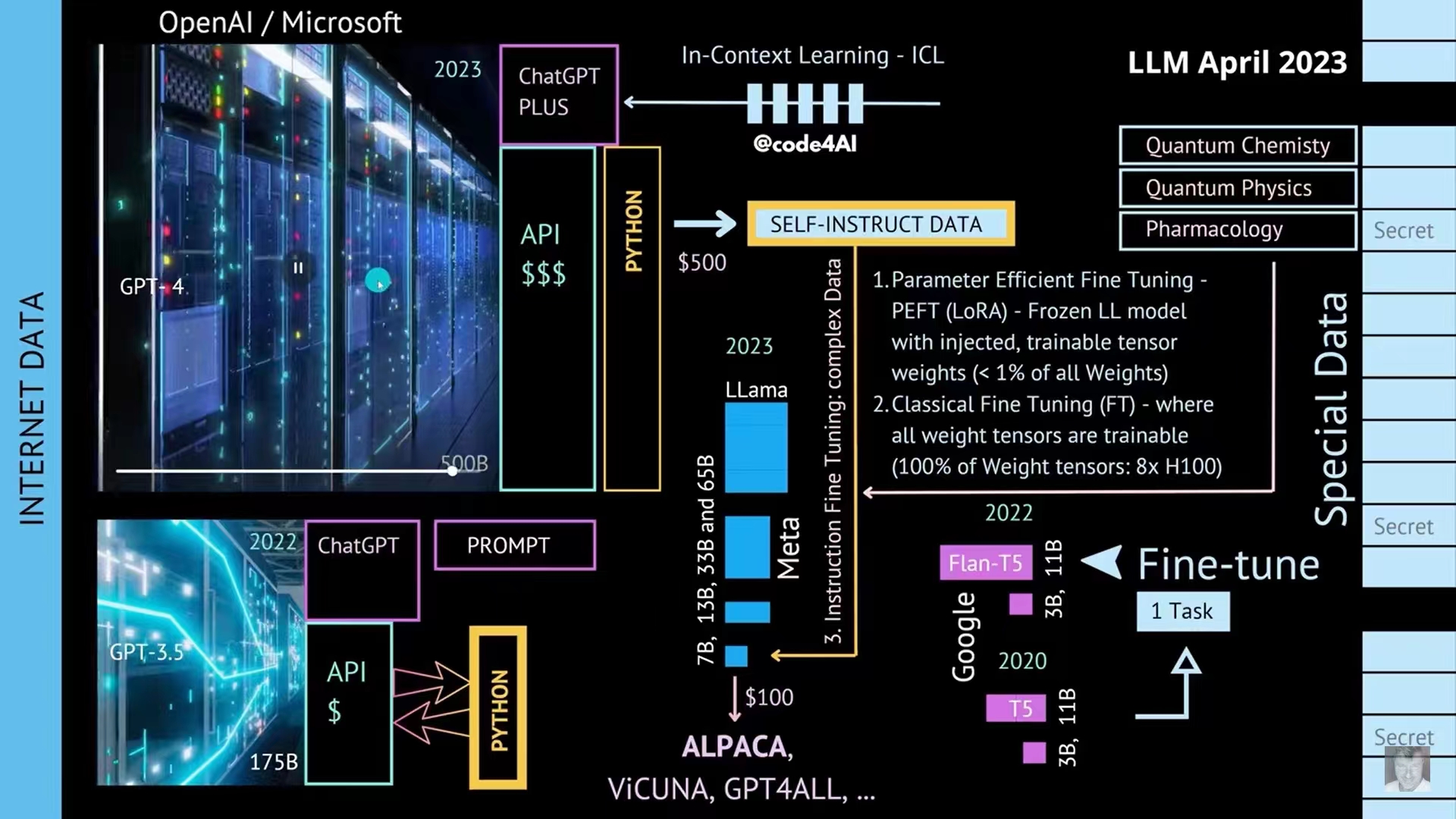
首先需要明确的是,象ChatGPT,GPT4那样的大模型,目前是没法私有化部署自己玩的,第一,人家没有开源,第二这者模型实在太大太重,训练成本太高—— 跟我预想的路径一样 —— ,只能先想办法"瘦身"大模型,再去用私有数据去训练,定制这个瘦身版 ,以下三种模式,采用的都是不同程度的"蒸馏瘦身"策略:
第一就是基于已有开源的预训练大模型,比如GPT-3,或者莫名其妙被泄露全部参数的Meta的LLama, 这些几百到上千亿参数的大家伙,用"冻住骨干参数,训练小部分参数"的办法,这就是附图的1: PEFT ,中文直译,参数经济型微调,说直白点,就是大模型的参数太多,都训练一遍,成本太高,承担不起,所以"锁定"大模型的大部分(骨干网络的)参数,只训练不到1%的参数。这样,训练一次的成本就大大降低了。这么干好处是可以重用一部分已经训练好的模型参数—— 也就是已有的"智商" ,缺点是,因为大模型的原理并不清晰,我们并不知道只调教某一部分参数,是否真的有效。
第二种,如果预算还行,可以找一个几十亿参数的小模型,比如基于Meta那个语言大模型LLama衍生出的小模型 ALPACA,或者谷歌的T5 (从六千万到110亿参数的版本都有),做一个整体私有化部署和训练,因为完全复刻了这个相对小的模型,模型的结构可以自己来调整,来折腾,所有参数可以自己训练,甚至有人会用针对大模型的提示词Prompt,生成一大堆类似的数据 —— 比如输入一首诗,让大模型变换时间,地点,主语,谓语,等等,再用这些生成的数据(被称为self- instruct data),去训练这个小模型,这就是所谓的用AI训练AI;这种模式缺点就是,因为模型没那么大,发挥不了那种大模型突然"涌现"的智能,毕竟个子小,没大哥们那么猛;
第三种,就是那些有私有数据,很想搞一些行业/领域模型,又有一定高质量私域数据的组织,还有一定预算的,比如附图的3: instruction fine tuning, 可以选择一条中间路径,选一个三五百亿参数的模型(开源的,比如Meta LLama的中等版),复刻下来,用自己的模型去调教,比如医学模型,量子物理模型,科研专业领域模型,等等。这么做好处是模型完全可以自己训练,自己调参,而且用的是专有数据,比较容易利用已有预训练模型的"智能",找出行业的模式和规律。
总而言之,言而总之,在大模型的机理没有搞清楚之前,要么只能忍受大模型不能调试的问题,要么就得承受私有化部署模型的高训练成本。选择何种方案,取决于成本,实现难度和收益的平衡。 细想想,所有新技术在初期应用时,不都是这样吗? —— 仅代表尹智个人观点 Ken's personal view only
