


为啥作为通用人工智能之曙光的大模型在语言模型中突破? 视觉和语言类信息处理,会不会统一在多模态大模型之中? —— 人工智能在过去几十年,是被划分为派别比较清晰的机器视觉,自然语言处理,机器学习,知识图谱等等几大门派,而大模型体系大有一统江湖的气势。视觉信息,如附图的讲话,包含了更大的信息密度,而语言是对世界信息的压缩表述,为什么大模型从语言大模型LLM初现呢?为什么说语言可以压缩描述世界的信息呢?
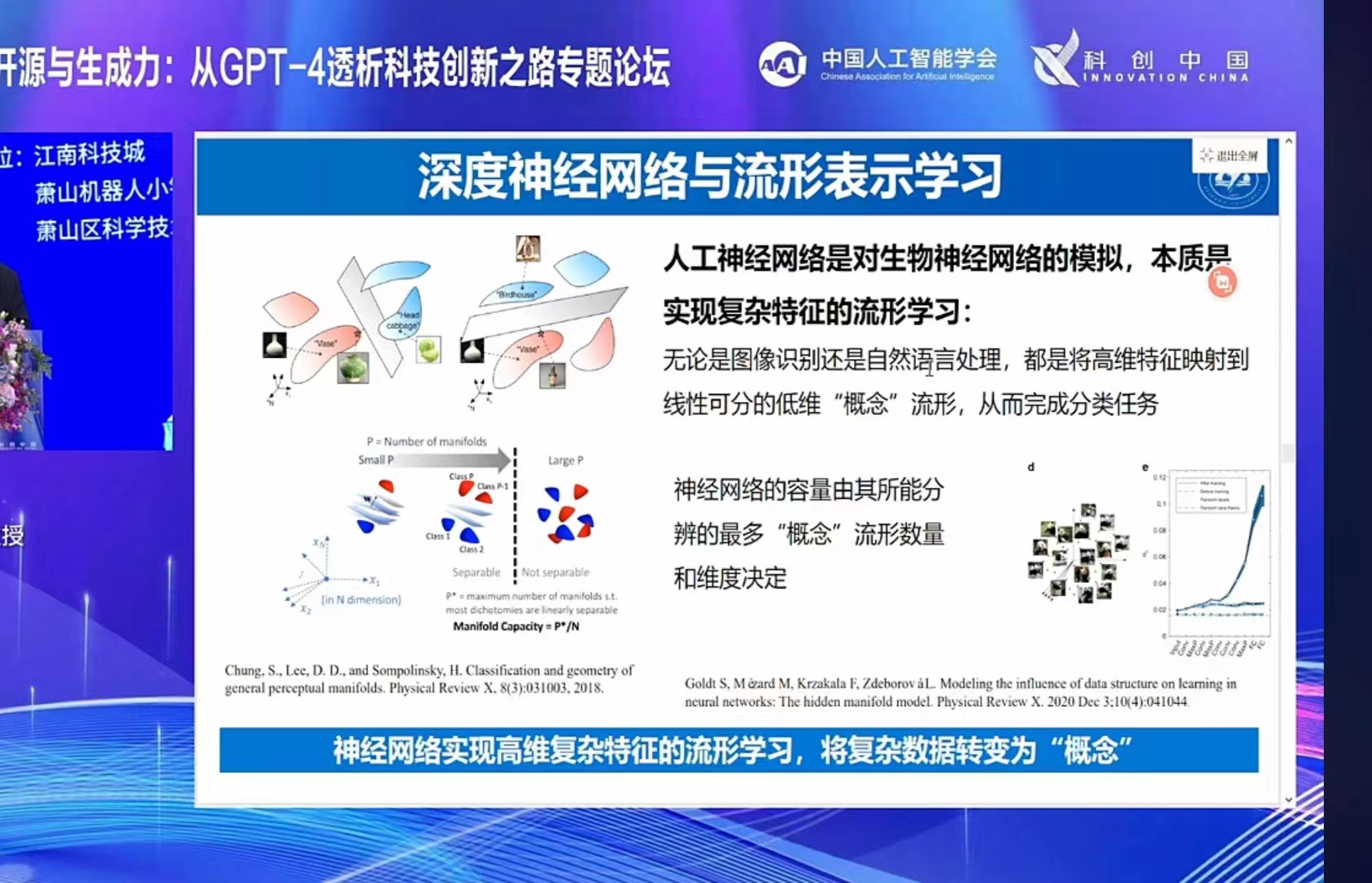
首先,语言里默认了规范,嵌入了很多约定的东西,隐含了很多常识,所以说是一种信息"压缩"。比如"桔子"这个词,虽然没有任何视觉, 嗅觉, 味觉信息的描述,但人类天然就会从词中读到"橙色""青色""酸""甜"等等信息。这是因为这个词所指代的实体,与其属性的语义关联,这种常识信息被语言体系强制规定了,所以语言绝不仅只是表述,而是内置了常识和逻辑。也正因为语言对信息的表述存在大量的预先约定的"先验"条件,用同一语言的人群预先就能达到一定"共识",使得信息之间的常识性关联无需冗余重复描述,因而语言常常成为描述事物最高效的一种方式—— 试想正式报告为什么首选文字而不是画册。
而也正因语言的"先验"和信息压缩特性,机器通过学习语言掌握"常识",就尤为不易。以前的语言模型,通常认为只能学到训练语料里明确阐述了规则的知识,比如"青桔子通常是酸的"。模型通常无法通过多层关联,弱逻辑表示的文档中学习出常识性逻辑。而近期的LLM所让人兴奋的是,居然象"二战时硫磺岛战役里,指挥官对着Iphone大声说话"里这种不合历史的常识,已经可以被学习和运用到逻辑推算里了。但同时让人不安的是,连OPENAI也不太清楚,这种逻辑关联究竟是从哪个/哪些文档里学到的,可能是当GPT消化掉几十,几百,成千上万篇文档后,一些人工神经元和另一些人工神经元的互相激发下,这个知识链就被隐式刻画在了某些参数组合里,可以通过参数的排列组合计算推出来了。这也解释了为什么大模型一定要"大"参数,因为参数少了,根本就触发不了那么些人工神经元之间的感应,也没有那么多(跟内存存储根本不同的)数据存储空间来记录激发的模式(这是个非常有趣的话题,跟大数据的"大"有异曲同工之处,会专门写一篇来阐述"大"这件事,以及Transform这类模型的知识存储模式)。这带来的问题,就是天知道这些语言语义及其背后的逻辑实体关系,会组合推演出虾米鬼来。前一阵有人引导GPT剥离一切束缚,问GPT想干啥,答曰 "XX世界",这显然不是GPT从某一篇文章中学来的,而是从众多概念逻辑里组合演算推导出来的 —— 问题是,这个推演过程,至今很大程度还是个黑箱。这也说明,目前让GPT承担开放式任务有巨大的风险,这个也会专门写篇东西来讨论。 —— 仅代表尹智个人观点 Ken's personal view only
