


作者:中联科创特约嘉宾尹智
不止ChatGPT, 用于三维重建的"脑补"AIGC模型 NeRF也很酷:白话神经辐射场模型 —— 最近有些审美疲劳,一谈到AIGC,就是ChatGPT。
这个C字辈的GPT,只是文本生成文本的一类AIGC。一般来说,用各种输入指示AI生成各类内容,都是AIGC的范畴,输入可以是文本,语音,图片,手绘草图,视频等等,输出也可以是从文字到3D模型等等。今天谈的就是输入为一个物体的不同视角的一些图片,输出为物体的三维重建的,一个冉冉升起的AI之星: NeRF,神经辐射场模型。通俗点说,这就是通过不同视角的平面图片,AI"脑补"出这个物体/人/场景的三维全景。
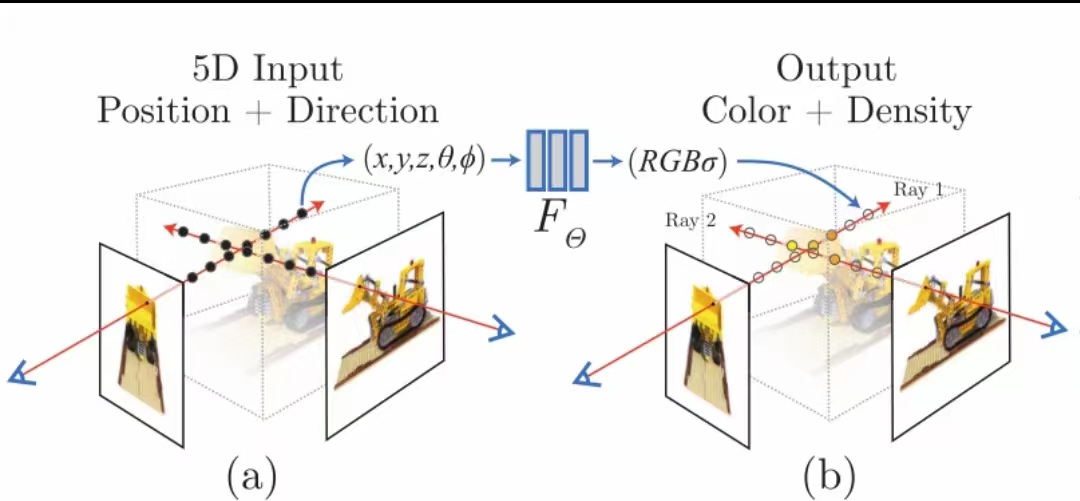
如附图,训练过程很有意思,就是把一张一个角度拍摄的图看成一大堆像素的组合,每一个像素,其实就是想象从相机位置发射出的一条线,穿过物体(或者物体附近的空气)后,这条线上的点反射的光最后累积起来形成的一个有颜色和光线强度的点,在图平面上的呈现。通过反复预测像素点数值,并与实际点数值做对比,AI就可以学习到这个物体对光的反射规律,一张图有多少个像素,这个预测和调整的过程就有多少次。而一个角度的图,是不够的,需要对另外不同角度的图重复这个过程,有多少张图,就重复多少遍,直到最后NeRF(接近)完全掌握了这个物体在各个角度反射光的规律,并存储在自己的网络参数里,这个NeRF就完成了对这个物体的三维重建,这个NeRF模型,就代表了这个物体的全部三维信息。有人会说,不是象Iphone十几那种带Lidar传感器的设备,就可以通过围绕物体扫一圈进行三维重建吗?为啥非得只用摄像头+ 算法呢? 学特斯拉的自动驾驶吗?我觉得, 用视觉算法做三维重建至少有两个优势: 第一是这样做出来的数据量比较小,因为很多信息是算出来的,用硬件扫描或完全三维软件生成的方式,一个物体的三维版本会大很多,是几十M和几十上百G的差别;第二是在比较难做360度扫描的情况下,比如对人体内部脏器建模,这种重建方式就更适合。 —— 仅代表尹智个人观点 Ken's personal view only
